정적 프로그램 분석 - 타입 분석
라온시큐어 핵심연구팀 이진재
정적 프로그램 분석 - 타입 분석
정적 분석 기술 중 하나인 타입 분석이 필요한 이유와 어떻게 타입 에러를 검출하는지 설명하는 글입니다.
정적 분석
정적 분석은 코드를 실행하지 않고 프로그램의 행동을 분석하고 예측하는 것을 말합니다.
때문에 프로그램 작성 단계에서 문제를 발견할 수 있고, 코드를 실행하지 않아도 되므로 비교적 적은 비용으로 분석이 가능합니다.
하지만 프로그램의 모든 경우를 실행하지 않고 예측하는 것이 힘든 경우도 있습니다.
int n;
scanf("%d", &n);
..
strcpy(dst, src, n);
..
위 예시 코드의 경우, n은 사용자의 입력값이 들어가기 때문에 프로그램을 실행하지 않고 n의 값을 예측하거나 프로그램의 문제를 찾기 힘들 수 있습니다.
우리는 정적 분석이 가지는 이러한 한계를 우회하기 위해 보수적으로 분석할 수 있습니다.
위 코드를 예시로 들면, “n의 값을 정확히 알아내는 것 보다, n이 가질 수 있는 모든 값을 구하자”는 생각입니다. 이는 정적 분석이 가지는 한계를 극복할 수 있지만, 오답이 포함될 수 있다는 단점이 있습니다.
타입 분석
프로그래밍 언어에는 특정 타입끼리만 가능한 연산이 있습니다. 예를 들어 파이썬의 경우 chr + int를 시도하면 타입 에러가 발생합니다.
타입 분석을 사용하면, 프로그램을 실행하기 전에 이러한 타입 오류가 존재하는지 검사할 수 있습니다.
간단히 하기 위해 다음과 같은 타입만 있다고 가정하겠습니다.
- 정수
- 포인터
- 함수
- 재귀 타입
포인터 타입의 표현
↑를 사용하여 표현하겠습니다.
↑int
위 표현식은 정수 포인터 타입을 의미합니다.
함수 타입의 표현
→ 를 기준으로 왼쪽에는 인자 타입이, 오른쪽에는 리턴 값의 타입을 명시합니다.
(int, int) → int
위 함수는 정수 2개를 받아서 정수 1개를 돌려주는 함수입니다.
재귀 타입의 표현
foo(x, p){
if(x == 0) a = 1
else a = x + p(x-1, p)
return a;
}
foo(1, foo)
위 함수처럼 인자로 자기 자신(함수)를 받는 경우, foo의 타입은 다음과 같습니다.
(int, (int, (int, ... ) ) ) → int
함수의 인자로 함수 타입이 오는 경우, 자기 자신을 인자로 받을 수 있기 때문에 재귀 타입이라는 것을 알 수 있습니다.
이렇게 재귀 타입을 간단히 표기하기 위해 관용적 표현인 μt. 를 사용하겠습니다.
μt.(int, t) → int
μs.(int, s) -> int // 이렇게도 쓸 수 있음.
List = μt.Empty ∣ Cons(head,t) // 리스트는 "빈 리스트 타입" 또는 "새로운 값(head)과 자기 자신(t)을 합친 리스트" 타입을 의미함
μ 뒤에 붙은 t가 함수의 2번째 인자로 들어가면, “이 함수의 두번째 인자는 자기 자신을 참조하는 재귀적 타입이다” 라고 해석할 수 있습니다.
타입 변수의 표현
타입 변수는 특정 변수의 타입을 나타내며, ‘[[’, ‘]]’ 로 감싸서 표시합니다.
[[y]] = int // y = 3
[[x]] = ↑int // x = &y
[[a(n,m)]] = (int, int) → int // func a(n, m){ ... return x+y }
타입 제약 시스템
타입 제약 시스템은 프로그램에 나오는 변수나 함수, 또는 표현식이 가질 수 있는 타입을 타입 변수로 표현한 것입니다. 타입 제약 시스템은 프로그램의 AST를 탐색하여 만들 수 있습니다.
입력 받은 프로그램을 한 줄씩 분석하여, 2. 에서 정의한 타입을 할당하여 ‘타입 제약 시스템’을 만듭니다. 타입 제약 시스템을 해결할 수 있다면(각 변수가 어떤 타입인지 구할 수 있다면) 해당 프로그램이 타입 오류가 없다고 볼 수 있습니다.
아래는 예시 코드를 타입 제약 시스템으로 표현한 것입니다.
add() {
var n,m,o;
n = 1;
m = input;
o = n+m;
return o;
}
위 예시 코드의 타입 제약 시스템을 만든다면 아래와 같습니다. ( [[X]]는 X의 타입을 의미 )
[[add()]] = () -> [[o]] // 인자를 받지 않고 변수 o와 같은 타입을 리턴하는 함수
[[n]] = int
[[input]] = int // 입력은 int 타입이라 가정
[[m]] = [[input]]
[[m]] = int // [[input]] = int
[[n+m]] = int
[[o]] = [[n+m]] = int
[[add()]] = () -> [[o]] = () -> int
Unification 알고리즘
타입 제약 시스템은 a = b 형식으로 표현됩니다. 각 줄에 있는 a,b에 대해 unify 연산을 적용하여 이 시스템이 해결 가능 한지를 확인할 수 있습니다.
각 타입 변수는 노드로 표현되며, 두 변수가 같은 부모 노드를 가리키는 경우 같은 타입이라고 볼 수 있습니다.
Unify 알고리즘
1. 두 변수 a,b의 루트 노드 a’, b’을 찾는다.
2. 만약 a’, b’가 같다면, a,b는 같은 타입이다.
3. 만약 서로 다르다면,
3-1. a’가 proper type(int, pointer 등)이고 b’는 아닐 때, b’의 부모 노드를 a’으로 설정한다
3-2. b’가 proper type이고 a’는 아닐 때, a’의 부모 노드를 b’으로 설정한다.
3-3. 둘 다 proper type인 경우, 하위 항에 대해 재귀적으로 unify 연산을 한다.
ex) ↑[[x]]의 경우, [[x]]가 하위 항임.
↑[[x]] = ↑[[y]] 가 나왔다면 a', b'의 하위항인 [[x]], [[y]]에 대해서도 unify 연산을 수행함.
4. 해당하는 경우가 없다면, 타입 에러다.
n = 1
m = n
이런 코드가 있고, 타입 제약 시스템이 아래와 같을 때
[[n]] = int
[[m]] = [[n]]
unification 알고리즘이 적용되는 순서는 아래와 같습니다.
- 초기화
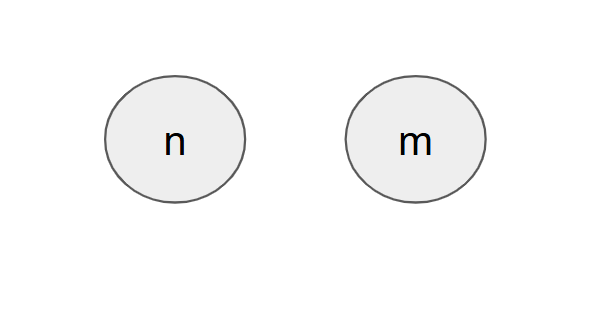
초기 노드 n, m은 루트 노드로 자기 자신을 가집니다.
- [[n]] = int
[[n]]의 루트노드는 자기 자신이며, 이는 proper type(여기선 int)가 아닙니다.
하지만 int의 경우 proper type이기 때문에 [[n]]의 루트 노드를 proper type인 int로 설정합니다.
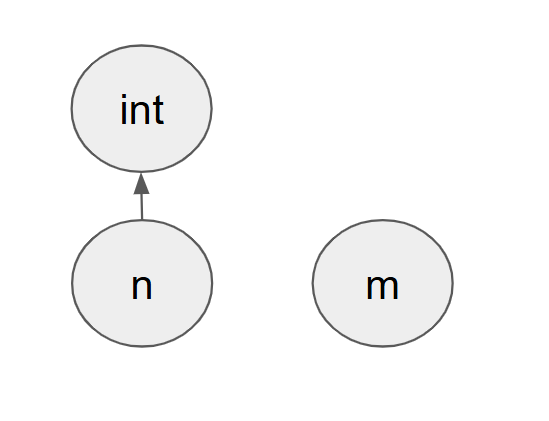
-
[[m]] = [[n]]
[[m]]의 루트 노드는 자기 자신이며, [[n]]의 루트노드는 proper type(int)입니다. 따라서 [[m]]의 루트노드를 [[n]]의 루트노드(=int)로 설정합니다.
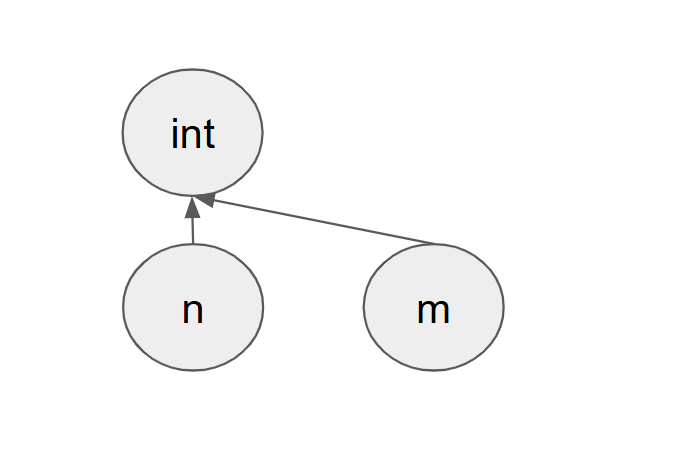
결과적으로 n, m은 타입이 int라는 솔루션이 나오기 때문에 해당 코드는 타입 에러가 발생하지 않는다고 판단할 수 있습니다.
타입 분석의 한계
- 제어 흐름을 고려하지 못함
특정 조건에 따라 타입이 달라지는 경우를 처리하지 못합니다.
func foo(x){
if [[x]] is 0:
return 123;
else if [[x]] is 1:
return 'abc';
이 경우, [[x]] = int = string 이 되어 타입 에러를 발생 시킨다고 잘못 추론할 수 있습니다.
- 다형성을 고려하지 못함.
이 코드는 에러가 발생하지 않지만 위 타입 분석 방법으로는 타입 에러가 발생한다고 잘못 추론할 수 있습니다.
func foo(x) { return x; }
a = foo(5);
b = foo('abc');
[[x]] = int = string이 되어 타입 에러를 발생 시킨다고 잘못 추론할 수 있습니다.
참고