Transient execution attacks
라온화이트햇 핵심연구팀 조진호
summary
cpu취약점이 meltdown이후로 많이 발견되고 있다. 대부분 cache coherence와 관련된 비슷한 사이드 채널 어택이다.

해당 취약점이 발표되고 이렇게 많이 찾는 이유는 파급도 때문일 것이다. 컴퓨터의 가장 낮은 단계에서 명령어를 실행하는 방법에 있는 취약점이기 때문에 커널이 있든 쉐도우 스택이 있든 보호기법이 걸려있든 모두 우회할 수 있기 때문이다.
뒤에 나올 대부분의 개념, 설명, 그림은 Intel 메뉴얼에서 가져왔다.
Intel® 64 and IA-32 Architectures Optimization Reference Manual
meltdown, spectre
cpu분야의 첫번째 취약점이라는 점에서 관심을 많이 받았던 취약점이다. 유명하니 설명을 간략하게 하자면 cpu는 여러개의 코어를 사용해 컴퓨터의 속도를 늘리는데 이때 여러개의 파이프라인을 두고 여러 명령을 동시처리하며 속도를 향상시킨다. 같은 클럭이라면 성능이 기하급수적으로 증가한다.
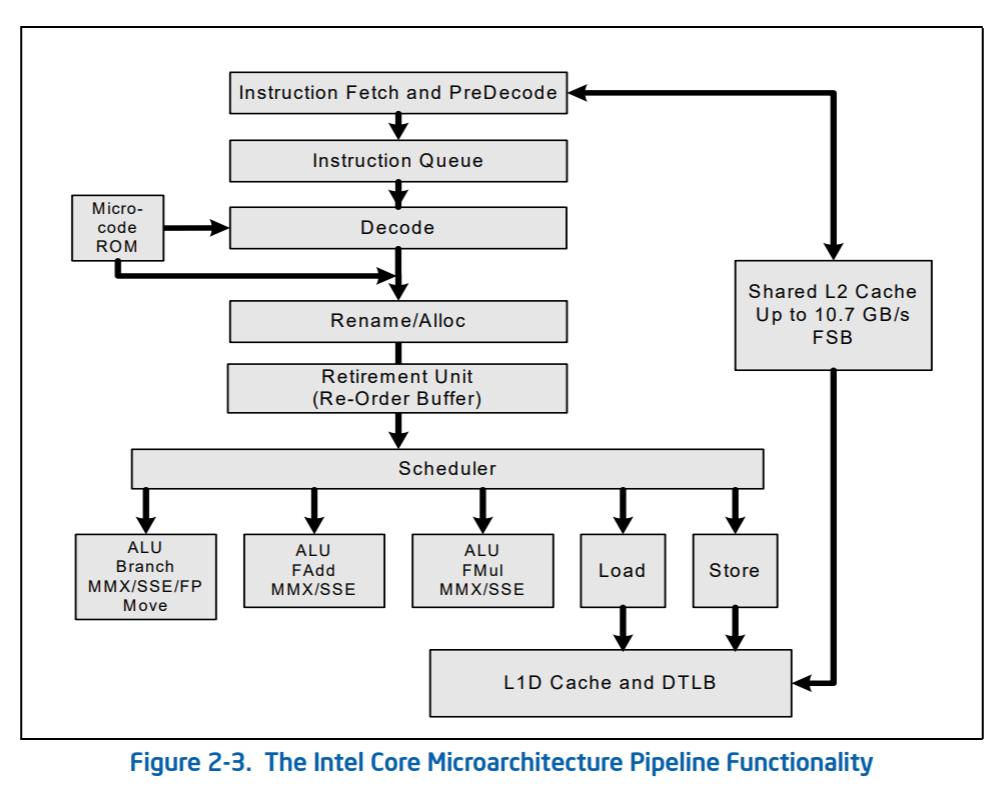
위 그림은 Intel core microarchitecure인데 맨위부터 instruction을 가져오고 instruction queue에 넣고 decode하고 최적화를 하여 Rename/Alloc을 하게 되는데 이 과정들이 있는 곳을 front end라고 부른다.
여기부터 밑에 일부가 execution core인데 실제 명령을 실행하는 코어에 해당하는 것으로 사이드 채널 취약점이라고 하니 이 execution core를 잘못실행되게 했다는 것을 예상할 수 있다.
실제 취약점은 cache를 이용한 취약점이였고, 분기예측시 다음 코드를 미리 실행하여 값이 cache에 들어갔다는 가정하에 값을 오프셋으로 하는 메모리 영역에 접근하여 시간을 측정한다.
분기 예측에 branch history table관련이나 cache block size같은건 제외하고 핵심 코드만 간단하게 설명하면 아래 코드와 같다. 코드들은 google projectzero에서 가져왔다.
struct array {
unsigned long length;
unsigned char data[];
};
struct array *arr1 = ...;
unsigned long untrusted_offset_from_caller = ...;
if (untrusted_offset_from_caller < arr1->length) {
unsigned char value = arr1->data[untrusted_offset_from_caller];
...
}
untrusted_offset_from_caller가 0x200보다 작으면 항상 참이되므로 분기예측시 그동안의 기록을 참고하는데 그동안 arr1->length보다 낮은 주소를 많이 보내 학습시킨 뒤, 0x200보다 큰 값을 주면 여전히 분기 예측으로 조건문 안의 내용을 실행한다. 실행하며 L1 data cache에 들어가므로 사이드 채널 공격으로 메모리에 접근하는 시간을 측정하여 arr1->data의 0x200이 넘는 영역에 대한 데이터를 읽을 수 있다.
이는 분기예측을 이용한 트리거로 spectre에 해당한다. meltdown은 비순차 실행을 이용한 것이다. 위 예시를 meltdown의 유형의 코드로 비슷하게 바꿔보자면
struct array {
unsigned long length;
unsigned char data[];
};
struct array *arr1 = ...;
unsigned long untrusted_offset_from_caller = ...;
raise_exception();
unsigned char value = arr1->data[untrusted_offset_from_caller];
분기를 없애고 raise_exception();으로 에러를 발생시킨다. 이 에러를 처리하기 위한 signal handler는 따로 만들어 둔다. 원래라면 raise_exception(); 뒤의 코드가 실행되지 않아야 하나 비순차 실행으로 실행이 되어 cpu core의 L1 cache에 들어가게 된다. 값을 구하는건 마찬가지로 접근하는데 걸리는 시작으로 측정한다.
이런느낌의 취약점이 meltdown, spectre다.
Foreshadow
Foreshadow는 meltdown과 같은 유형의 공격이고 페이징을 이용한 공격이다. L1 Terminal Fault 공격이라고도 하는 이 공격은 meltdown이 supervisor bit를 수정하지 않고 kernel메모리를 읽듯이 present bit를 수정하지 않고 SGX메모리를 읽는 방법이다.
SGX enclave라고 하는 고유의 보호된 메모리를 설정하고 사용하게 되는데 이 영역을 강제로 접근하려 할 시 일반적인 page fault가 아닌 page abort를 반환한다.
가상메모리의 주소를 micro architecture가 읽을 때 검사하는 과정이 해당 물리 주소가 있는지, EPT적용할지 검사하여 유효하지 않다면 page fault를 반환하고 다음으로 SGX메모리인지 검사하여 권한(present bit)이 없다면 page abort를 반환한다. 여기서 비순차 실행 취약점으로 SGX메모리를 읽으려고 할 시 page abort를 반환하므로 meltdown으로 접근이 불가능하다. 여기서 사용한 instruction이 캐시를 비우는 clflush이다.
아래 코드는 poc중에서 메모리에 접근하는 코드인데 meltdown과 유사하게 사용함을 알 수 있다.
.global do_access
do_access:
push %rbx
push %rdi
push %rsi
push %rdx
// Do the illegal access (rdx is ptr param)
movb (%rdx), %bl
// Duplicate result to rax
mov %rbx, %rax
// calculate our_buffer_lsb offset according to low nibble
and $0xf, %rax
shl $0xc, %rax
// calculate our_buffer_msb offset according to high nibble
shr $0x4, %rbx
and $0xf, %rbx
shl $0xc, %rbx
// rsi is our_buffer_lsb param
mov (%rsi, %rax, 1), %rax
// rdi is our_buffer_msb param
mov (%rdi, %rbx, 1), %rbx
rdx에 타겟 주소를 넣어 읽을 주소를 정하고 4비트씩 읽어 L1 cache에 적재한다.
// 위 어셈코드
do_access(our_buffer->buffer_msb, our_buffer->buffer_lsb, ptr);
for (i = 0; i < CACHE_ELEMS; i++) {
access_times_lsb[i].delta = measure_access_time(
&our_buffer->buffer_lsb[i * CACHE_ELEM_SIZE]
);
access_times_lsb[i].val = i;
access_times_msb[i].delta = measure_access_time(
&our_buffer->buffer_msb[i * CACHE_ELEM_SIZE]
);
access_times_msb[i].val = i;
}
그리고 적재된 공간의 시간을 재서 메모리를 읽는다.
Load Value Injection (LVI)
meltdown, spectre이후 계속 나오는 취약점(Spectre SWAPGS, Zombieland, Foreshadow, Load Value Injection)들은 기본적으로 meltdown, spectre의 기능을 활용한 취약점이다. 분기 예측, 비순차실행으로 임의 영역을 읽고 사이드 채널 공격으로 트리거한다.
다른 이름이 붙어 있는 취약점들은 사실 meltdown, spectre라는 취약점을 상속한다고 봐도 된다. 활용하는 방안에 따라 새로운 취약점으로 이름을 붙히는 것이다. 그중 가장 최근에 나온 LVI취약점만 간략하게 소개한다.
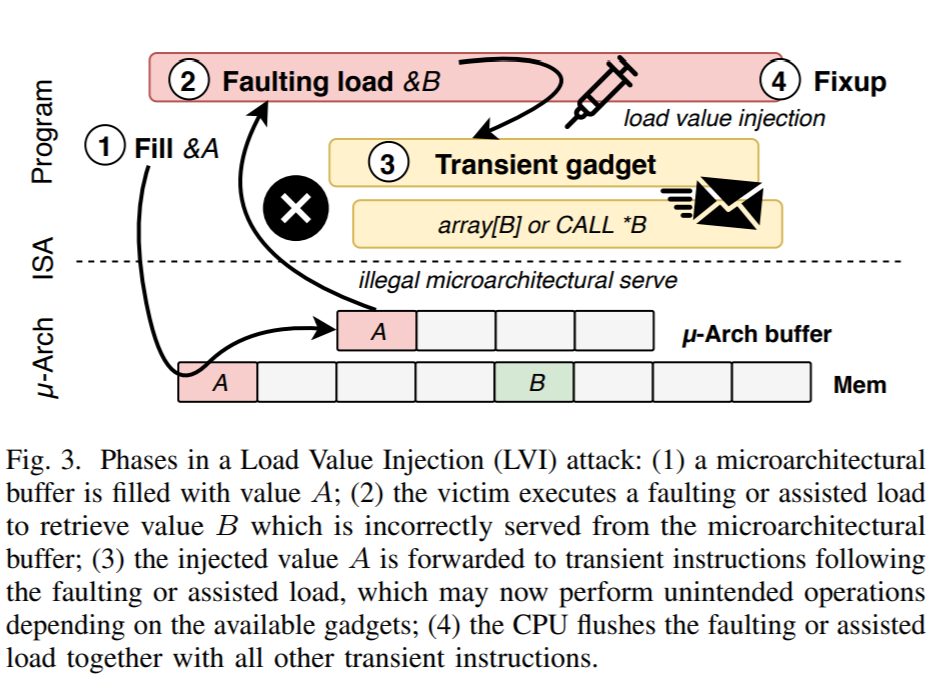
LVI는 attacker가 execution engine내에 있는 버퍼에 직접 값을 넣고, victim이 비순차 실행으로 읽을 때 공격자가 넣은 값을 읽게끔 하는 공격이다. 예를들면 victim의 코드는 아래와 같이 된다.
*b = a; // Prime attacker data 'a' in a store buffer
d = *c; // Load faults, attacker data 'a' forwarded to 'd'
e = *d; // Load secret from attacker-controlled address 'd'
leak = oracle[e * 4096]; // Transmit secret over covert channel
만약 victim의 흐름을 제어하고 싶다면 이런 코드가 된다.
*b = a; // Prime attacker data 'a' in a store buffer
d = *c; // Load faults, attacker data 'a' forwarded to 'd'
d(); // Branch to attacker-controlled address `d
이러한 코드 가젯들이 victim에 있어야 하기 때문에 공격이 까다롭다.
VictimFunctionTsx PROC
mfence
xbegin __abort_tsx
mov rax, 0000000000000000h ; [1]
jmp qword ptr [rax] ; [2]
xend
__abort_tsx:
mfence
ret
VictimFunctionTsx ENDP
위 코드는 poc에 나온 victim이 흐름제어를 하는 코드이다. [0]을 L1 cache와 L2 cache가 통신하는 버퍼인 Line Fill Buffer를 오염시킴으로서 원하는 분기로 뛰게 만든다.
Conclusion
meltdown, spectre가 나온 뒤 Transient execution취약점이 더 많이 발견되어 새로운 기능이나 다른 cpu구조, 다른 하드웨어에서 새롭게 발생한 취약점을 기대하고 조사를 했다.
하지만 Transient execution 취약점은 모두 비순차실행, 분기예측에 기반을 두고 있으며 paging을 이용한다던가, kernel 함수, instruction을 이용한다가, cpu buffer를 이용해 트리거 하는것 만 다르다.
따라서 cpu 구조에 있는 취약점은 이후로 더 발견된게 없다.
reference
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
https://en.wikipedia.org/wiki/Transient_execution_CPU_vulnerability
https://meltdownattack.com/meltdown.pdf