HTTP Header 순서를 이용한 정상 브라우저 구분에 대한 연구
라온화이트햇 핵심연구팀 김재성
이슈
얼마 전 특정 사이트에 대한 분석을 하던 도중 재미있는 사실 하나를 발견했습니다.
해당 사이트는 curl, wget과 같은 command line 도구들을 이용한 웹 요청을 차단하고 있었는데, 정상 브라우징 처럼 보이기 위해 Cookie, User-Agent 등 모든 헤더를 맞춰 전송한 요청 역시 서버에서 응답을 반환하지 않는 문제였습니다.
GET / HTTP/1.1
Host: target.example.com
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
위는 브라우저에서 정상적으로 target.example.com에 접속했을때 전송된 패킷입니다.
import requests
s = requests.session()
headers = {
"Host":"target.example.com",
"Connection":"keep-alive",
"Pragma":"no-cache",
"Cache-Control":"no-cache",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7"
}
r = s.get("http://target.example.com", headers=headers)
print(r.text)
그리고 요청 패킷을 보고 동일한 웹 요청을 하는 코드를 위와 같이 python으로 작성할 수 있습니다.
GET / HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36
Accept-Encoding: gzip, deflate
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Connection: keep-alive
Host: target.example.com
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
얼핏 코드 상으로 봤을 땐 완전히 동일한 요청을 날리는 것처럼 보이지만 실제로는 위와 같이 브라우저 요청과 Python requests로 전송한 요청은 헤더 순서가 달랐습니다.
헤더 순서까지 맞춰서 보내면 웹 서버로부터 정상적으로 응답이 오는 것을 확인했으므로 requests 모듈에서 원하는 헤더 순서대로 요청할 수 있도록 문제 해결을 시도하였습니다.
문제 해결
requests 모듈 대신 urllib3 등 다른 모듈을 사용하면 문제를 해결할 수 있지만 헤더 순서 문제로 requests의 편의성을 포기하긴 어려워 원인 분석을 해보았습니다.
import requests
headers = {
"BadSpell": "1",
"X-CSRF-TOKEN": "AA=AA",
"ABCD": "abcd"
}
requests.get("http://0:1337", headers=headers)
"""
root@sdev:~# nc -lvp 1337
Listening on [0.0.0.0] (family 0, port 1337)
Connection from localhost 60682 received!
GET / HTTP/1.1
Host: 0:1337
**User-Agent: python-requests/2.22.0
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-alive**
BadSpell: 1
X-CSRF-TOKEN: AA=AA
ABCD: abcd
"""
간단한 requests 예제로 테스트를 하면 headers 변수에 임의 헤더를 넣고 전송하였을 때 사용자가 지정한 custom 헤더 순서는 변하지 않았지만 별도 preload된 헤더가 포함된 것을 확인할 수 있습니다. 이 때문에 User-Agent, Connection 등의 헤더를 덮어도 dict 순서가 바뀌지 않고 requests 모듈로 요청하는 모든 요청의 첫번째 헤더 순서는 User-Agent가 됩니다.
...
def default_headers():
"""
:rtype: requests.structures.CaseInsensitiveDict
"""
return CaseInsensitiveDict({
'User-Agent': default_user_agent(),
'Accept-Encoding': ', '.join(('gzip', 'deflate')),
'Accept': '*/*',
'Connection': 'keep-alive',
})
...
https://github.com/psf/requests/blob/3e7d0a873f838e0001f7ac69b1987147128a7b5f/requests/utils.py
...
class Session(SessionRedirectMixin):
...
__attrs__ = [
'headers', 'cookies', 'auth', 'proxies', 'hooks', 'params', 'verify',
'cert', 'adapters', 'stream', 'trust_env',
'max_redirects',
]
def __init__(self):
#: A case-insensitive dictionary of headers to be sent on each
#: :class:`Request <Request>` sent from this
#: :class:`Session <Session>`.
**self.headers = default_headers()**
#: Default Authentication tuple or object to attach to
#: :class:`Request <Request>`.
self.auth = None
...
https://github.com/psf/requests/blob/80011a7917afe2cd6a5fa8359e7ea90203880b3c/requests/sessions.py
github requests 소스코드의 일부를 보면 preload 헤더는 Session 객체가 생성될 때 default_headers 함수를 호출하여 self.header를 초기화되는 것을 확인할 수 있습니다. 따라서 사용자가 s = requests.session()로 세션을 만들고 s.headers를 한번 더 초기화하는 방식으로 preload 헤더를 제거할 수 있습니다.
import requests
s = requests.session()
**s.headers = requests.structures.CaseInsensitiveDict()**
headers = {
"BadSpell": "1",
"X-CSRF-TOKEN": "AA=AA",
"ABCD": "abcd"
}
s.get("http://0:1337", headers=headers)
"""
root@sdev:~# nc -lvp 1337
Listening on [0.0.0.0] (family 0, port 1337)
Connection from localhost 60702 received!
GET / HTTP/1.1
Host: 0:1337
**Accept-Encoding: identity**
BadSpell: 1
X-CSRF-TOKEN: AA=AA
ABCD: abcd
"""
수정된 코드를 실행하면 User-Agent , Accept 등 일부 헤더가 제거되어 전송됩니다. 지정하지 않은 Accept-Encoding 헤더가 여전히 포함되어있지만 사용자가 헤더 선언 이후에 update 되는 헤더이므로 헤더 순서에는 영향을 미치지 않습니다.
이제 정상 브라우저와 완전히 동일한 요청을 보낼 수 있게 되고 크롤링도 가능해졌습니다.
Header 순서를 이용하여 정상 브라우저 구분이 가능한가?
GET / HTTP/1.1\r\n 대신 GET / HTTP/1.1\n 으로 Carriage Return이 없는 비표준 형식의 웹 요청을 보내거나 누락된 헤더가 있거나 잘못된 헤더를 전송하였을 때 400 응답을 반환하는 웹서버는 본적이 있지만 헤더 순서에 따라 응답을 반환하지 않는 웹서버는 흔하지 않기에 두 가지의 의문을 가질 수 있습니다.
-
헤더 순서에 따라 응답을 반환하지 않는 방식은 크롤러 등을 차단하기 위해 의도한 것인가? 이에 대한 직접 증명은 어렵지만, 웹사이트의 규모와 이용자 수를 감안하였을 때 원하는 헤더 순서가 오지 않았을 때 응답을 제대로 처리하지 못할 가능성보다는 방화벽에서 의도적으로 처리했을 가능성이 높을 것입니다.
-
의도한 것이라면 헤더 순서에 따른 정상 브라우저 구분 방식은 신뢰할 수 있는가?
웹 서버에서 의도했던 의도하지 않았던 정상 브라우저를 걸러내는 용도로 사용할 수 있도록 충분한 검증을 한다면 크롤링 등의 봇 요청을 필터링할 수 있을 것이라 판단할 수 있습니다.
하지만 문제의 사이트에서도 헤더 순서에 따른 접속 차단은 특정 IP대역(클라우드 호스팅, 해외 IP 등)에서만 제한적으로 이루어지고 있었으므로(정상 이용자에 대한 오탐 최소화로 추정) 모든 요청에 대해 적용하려면 많은 테스트가 필요합니다. 또한, RFC2616(https://tools.ietf.org/html/rfc2616#section-7.1) 문서에도 HTTP 요청 헤더 순서에 대한 내용이 없으므로 브라우저의 업데이트로 얼마든지 요청 헤더 순서에 변동이 생길 수 있음을 감안해야합니다.
검증 및 간단한 구현
요청 헤더 순서에 따른 차단 검증 및 구현을 위해 사용자들이 주로 쓰는 브라우저로 target.example.com에 접속하였을 때의 헤더 순서를 표로 정리하였습니다.
브라우저마다 요청 헤더 순서가 상이하지만 User-Agent로부터 브라우저 정보를 확인할 수 있으므로 미리 조사한 브라우저의 요청 헤더 순서와 대조하는 방법으로 정상 브라우징 여부를 쉽게 판단할 수 있습니다.
#!/usr/bin/env python3
from flask import Flask, request, Response
app = Flask(__name__)
@app.before_request
def before_request():
if request.user_agent.string.find("Chrome") != -1:
chrome_seq = ["Host", "Connection", "User-Agent", "Accept", "Accept-Encoding", "Accept-Language"]
for key in request.headers.keys():
if key not in chrome_seq:
continue
if key != chrome_seq[0]:
return Response("Abnormal request", status=400)
del chrome_seq[0]
if len(chrome_seq):
return Response("Abnormal request", status=400)
@app.route("/", methods=["GET"])
def hello():
return "Hello world"
if __name__ == "__main__":
app.run(host="0.0.0.0", port=4444, threaded=True, debug=True)
위 코드는 User-Agent가 Chrome일 경우 정말 해당 브라우저가 Chrome인지 저장된 Chrome 헤더 순서와 일치하는지 확인하고 일치하지 않으면 Status code(400)을 반환하도록 설계된 웹서버입니다.
Chrome의 헤더 순서로 Host, Connection, User-Agent, Accept, Accept-Encoding, Accept-Language 순으로 오지 않거나 누락된 헤더가 있을 경우 비정상적인 접속으로 판단하여 Abnormal Request가 출력됩니다. (중간에 다른 헤더 삽입 허용)
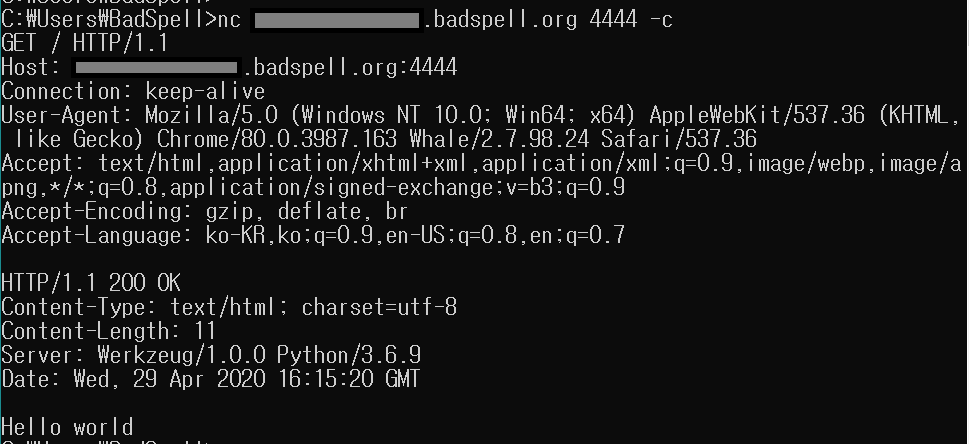
# 정상 요청(Hello world)
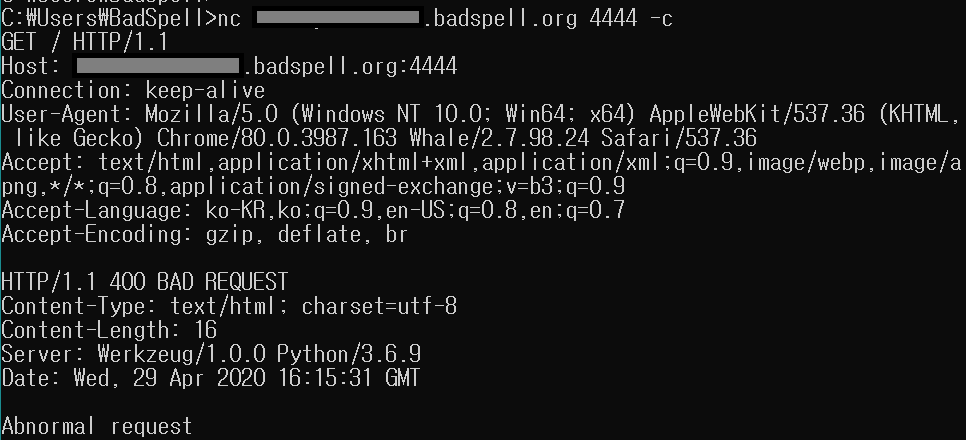
# 비정상 요청(Abnormal request)
그림과 같이 Chrome 헤더 순서를 올바르게 보냈을때 Hello world가 출력되고 Accept-Language와 Accept-Encoding 헤더 순서를 바꿔서 요청하면 400 응답을 반환하여 잘 차단되는 것을 확인할 수 있습니다.